Cómo Convertir Variables Categóricas a Numéricas sin Romper tu Modelo
Una guía práctica de Ignacio Urteaga, Director Académico del Instituto Data Science
En esta nueva entrega, Ignacio Urteaga, Director Académico del Instituto Data Science, comparte una aventura de descubrimiento que debería estar en el manual de todo científico de datos: qué pasa cuando convertimos variables categóricas a numéricas de forma incorrecta, y cómo elegir la estrategia adecuada según el tipo de dato y el objetivo del modelo.
El artículo recorre tres enfoques distintos sobre un mismo dataset real de un call center, mide su impacto en una métrica económica concreta, y desmonta una idea peligrosamente difundida: que la tasa de aciertos alcanza para comparar modelos.
¿Por qué necesitamos convertir variables categóricas?
Muchas variables con alto poder predictivo llegan al dataset en formato categórico: nivel de estudios, nivel socioeconómico, localidad, marca de tarjeta de crédito, modalidad de línea telefónica, entre otras. Algunos algoritmos —como los árboles de decisión— las procesan sin problema. Otros, como vecinos cercanos o redes neuronales, solo aceptan entradas numéricas.
La pregunta práctica es entonces ineludible: ¿cómo pasamos de categorías a números sin perder el poder predictivo de la variable?
Variables categóricas ordenables vs no ordenables
Antes de elegir un método, hay que distinguir dos tipos de variables categóricas:
- Ordenables: la naturaleza del dato genera una escala. Por ejemplo, nivel socioeconómico (de A1 a E) o nivel de estudios alcanzado (primario, secundario, terciario, universitario). Acá tiene sentido asignar números que preserven el orden: lo cercano queda cerca, lo lejano queda lejos.
- No ordenables: no existe un orden natural. Localidad, marca de tarjeta, origen de lista. Forzar una escala numérica acá es donde empiezan los problemas.
Para las ordenables, asignar 1, 2, 3, etc. funciona bien. Para las no ordenables, hace falta otra estrategia.
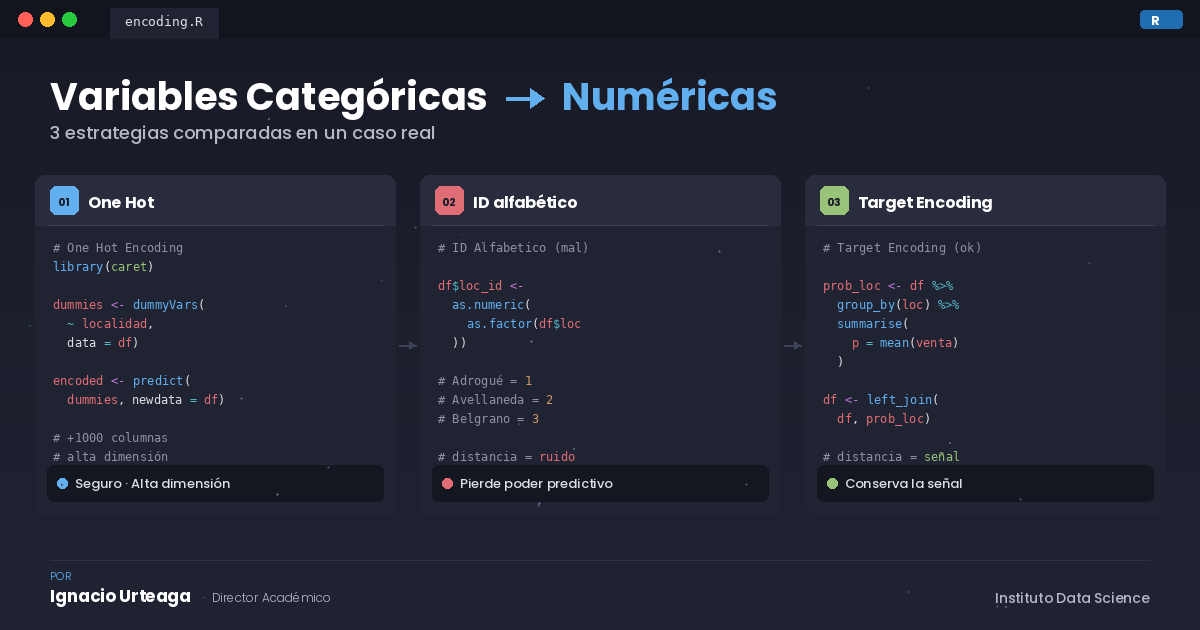
Tres estrategias para convertir variables categóricas a numéricas
One Hot Encoding
La opción «segura» por defecto: por cada valor posible de la categoría se crea un atributo binario (1 si pertenece, 0 si no). Es simple y robusto.
Limitación: cuando la variable tiene miles de categorías (por ejemplo, miles de localidades), el dataset explota en dimensionalidad. Una red neuronal con miles de entradas se vuelve difícil de entrenar y propensa al sobreajuste.
Codificación por ID alfabético (la opción tentadora)
Tomar las categorías, ordenarlas alfabéticamente y asignar un número correlativo a cada una. Es rápido y no infla las columnas. Pero hay un problema conceptual grave: la distancia numérica entre IDs no refleja ninguna relación real entre las categorías. Que «Adrogué» tenga ID 1 y «Avellaneda» ID 2 no significa que sean parecidas para el modelo.
La intuición de Ignacio antes del experimento era clara: esto no debería andar bien.
Codificación por target encoding (probabilidad histórica)
Reemplazar cada categoría por un valor numérico que resume el aporte histórico de esa categoría a la predicción. En el caso del call center, cada localidad se reemplaza por su probabilidad de venta histórica. La distancia numérica ahora sí refleja una relación significativa para el modelo.
El experimento: tres árboles, un mismo dataset
El dataset y el problema de negocio
Para validar empíricamente cada estrategia, Ignacio usó datos reales de un call center que vendía electrónica mediante llamadas en frío. Cada contacto tenía un costo fijo y cada venta concretada generaba una ganancia neta. La pregunta de negocio era directa: ¿a quién deberíamos llamar para maximizar la ganancia?
Las variables disponibles incluían año de contacto, marca de tarjeta de crédito, modalidad de línea telefónica (fija, CPP o MPP), localidad, origen de lista y resultado de la llamada.
Por qué árboles de decisión
Se eligieron árboles de decisión por dos razones técnicas:
- Aceptan tanto datos numéricos como categóricos, lo que permite comparar las tres estrategias usando exactamente el mismo algoritmo.
- Reportan importancia de variables, métrica que ayuda a entender qué le aporta poder predictivo al modelo.
Los tres árboles entrenados
- Árbol 1: localidad como variable categórica nativa.
- Árbol 2: localidad reemplazada por ID alfabético numérico.
- Árbol 3: localidad reemplazada por probabilidad histórica de venta (target encoding).
Tratamientos preliminares
Antes de entrenar, hubo que resolver dos cuestiones técnicas habituales:
- Categorías raras: si una localidad aparecía en el set de prueba pero no en el de entrenamiento, el modelo no podía predecir. Solución: filtrar categorías con muestras insuficientes.
- Desbalanceo de clases: las ventas son raras por naturaleza (por eso se buscan). Aplicar down sampling sobre la clase mayoritaria permitió que el modelo aprendiera de las ventas reales en lugar de optimizar por mayoría.
Resultados que sorprenden: cuando la métrica miente
Importancia de variables: la intuición confirmada
Los tres árboles devolvieron resultados consistentes con la intuición previa:
- En el Árbol 1, la localidad apareció como la variable más importante.
- En el Árbol 2, el ID alfabético perdió mucha relevancia.
- En el Árbol 3, la probabilidad histórica recuperó importancia.
Hasta ahí, todo parecía calzar.
Tasa de aciertos: el shock
Al comparar los tres modelos por tasa de aciertos sobre el conjunto de prueba, los resultados fueron prácticamente idénticos. Diferencias mínimas, no significativas. «No entiendo nada, me tiraron el bochín al fondo», comenta Ignacio en el video. La intuición decía que el Árbol 2 debía ser claramente peor, pero la métrica decía que daba lo mismo.
Métrica económica: la diferencia que sí importa
Aquí ocurrió el insight clave del experimento. Cuando se midieron los tres modelos contra una métrica económica de negocio —ganancia neta de la operación, considerando el costo de cada contacto y la ganancia de cada venta— las diferencias se hicieron evidentes y materiales.
El Árbol 2 (ID alfabético) perdía plata respecto a los otros dos. El orden de magnitud era significativo: en el contexto del call center, la diferencia se medía en millones.
Por qué la tasa de aciertos te puede engañar
La razón técnica detrás del fenómeno es simple, pero suele pasarse por alto: la tasa de aciertos trata todos los errores como equivalentes.
- Llamar a alguien que no compra (falso positivo) cuesta el contacto.
- No llamar a alguien que hubiera comprado (falso negativo) cuesta la ganancia perdida.
Esos dos costos no son iguales, y en la mayoría de los problemas de negocio nunca lo son. Si optimizás hiperparámetros con tasa de aciertos, vas a estar optimizando para un objetivo que no es el del negocio. Cuando después comparás modelos con la métrica económica, ya ninguno está bien afinado.
La regla práctica
Trabajá desde el primer momento con una métrica concreta del negocio: pesos, vidas salvadas, conversiones, ahorro de tiempo. Algo que le importe a la organización para la cual estás construyendo el modelo.
Esto garantiza que todo el pipeline —selección de features, optimización de hiperparámetros, comparación de modelos, elección del umbral de clasificación— esté alineado con el resultado que el cliente realmente busca.
Conclusiones del experimento
El recorrido deja tres conclusiones prácticas para todo científico de datos:
- Reemplazar categorías por IDs alfabéticos puede destruir poder predictivo, aunque la tasa de aciertos no lo refleje. No es una verdad universal, pero a partir del primer caso documentado, la práctica queda bajo sospecha.
- One Hot Encoding y target encoding son alternativas más confiables, cada una con su trade-off entre dimensionalidad y dependencia de la variable objetivo.
- La métrica de evaluación debe ser la métrica del negocio, no una métrica abstracta como accuracy, F1-score o AUC. Las métricas abstractas pueden ocultar diferencias económicas significativas.
Más allá del caso puntual, la lección es metodológica: la elección de la métrica de evaluación es tan crítica como la elección del algoritmo.
Mirá la presentación completa en video
🎬 Ver el video en YouTube: ¿Estás arruinando tus modelos? El error oculto al convertir variables categóricas
Sobre el autor
Ignacio Urteaga es Director Académico del Instituto Data Science. Lidera el diseño y la actualización de los planes de estudio de las diplomaturas y comparte regularmente contenido técnico orientado a científicos de datos en formación y profesionales en ejercicio.